Stammdatenqualität im Krankenhaus: Schritt für Schritt zu sauberen Daten für bessere Patientenergebnisse
-
 Adrian Bedö, Senior Product Manager Content Solutions
Adrian Bedö, Senior Product Manager Content Solutions

Die Zukunft des Gesundheitswesens hängt auch von der Datenqualität ab. Nur wenn die Daten auf beiden Seiten der Lieferkette synchron, fehlerfrei und umfassend sind, können Prozesse optimiert und die Patientenversorgung verbessert werden. Schlüssel zum Erfolg ist ein Fünf-Phasen-Modell, das sicherstellt, dass die Stammdatenqualität im Krankenhaus hoch ist – und auch dauerhaft hoch bleibt.
- Die Erkenntnis: Das Gesundheitswesen braucht verlässliche Daten
- Der Status Quo: Datenqualität im Krankenhaus noch immer überschaubar
- Die Folge: Steigende Kosten in den nachgelagerten Prozessen
- Die Gründe: Herausforderungen im Datenmanagement für Lieferanten und Krankenhäuser
- Der Prozess: Fünf Schritte auf den Weg zu einer besseren Stammdatenqualität im Krankenhaus
- Die Erkenntnis: Effiziente Stammpflege im Krankenhaus geht nur über digitale Lösungen
Die Erkenntnis: Das Gesundheitswesen braucht verlässliche Daten
Krankenhausreform, Fallpauschale, Sonderentgelte – dieser Tage wird wieder viel darüber diskutiert, wie die Zukunft des deutschen Gesundheitswesens aussehen sollte. In einem Punkt sind sich zumindest alle einig: Daten spielen dabei eine zentrale Rolle. Ob Krankenhaus oder Lieferant, beide Seiten der Lieferkette benötigen aktuelle und fehlerfreie Daten, um Prozesse zu optimieren, die Kosten für die Versorgung zu senken und so die Patientenergebnisse zu verbessern.
Zu dieser Erkenntnis kommen auch die Geschäftsführer und ärztlichen Direktoren der 600 größten deutschen Kliniken, die im Rahmen der diesjährigen Roland Berger Krankenhaus-Studie befragt wurden. Sie sehen in der Zunahme der individualisierten Medizin durch Daten und eine bessere Planbarkeit der Leistungsinanspruchnahme durch Data Analytics zwei Themen, die in den nächsten Jahren an Relevanz gewinnen werden. Im Zuge der Digitalisierung bildet die Datenqualität die Grundvoraussetzung für zwei ebenfalls benannte Kernthemen: optimierte Prozesse und eine erhöhte Effektivität in der Leistungserbringung.
Der Status Quo: Datenqualität im Krankenhaus noch immer überschaubar
Obwohl das Bewusstsein für die Gewinnung und Nutzung von hochwertigen Daten gestiegen ist, wird das Thema im Gesundheitswesen leider noch immer stiefmütterlich behandelt. In einer Umfrage der Sana Einkauf & Logistik GmbH aus dem Jahr 2021 gaben 45,9% der befragten Industriepartner an, dass die Datenqualität in ihren Systemen unzureichend ist. Weil die Produktdaten falsch oder unvollständig sind, wird logischerweise auch die Stammdatenpflege im Krankenhaus zur Herausforderung. Die Gründe dafür sind vielschichtig – von fehlenden Informationen für die Artikelanlage über falsche Barcodes bis hin zu ineffizienten Prozessen in der Materialwirtschaft.
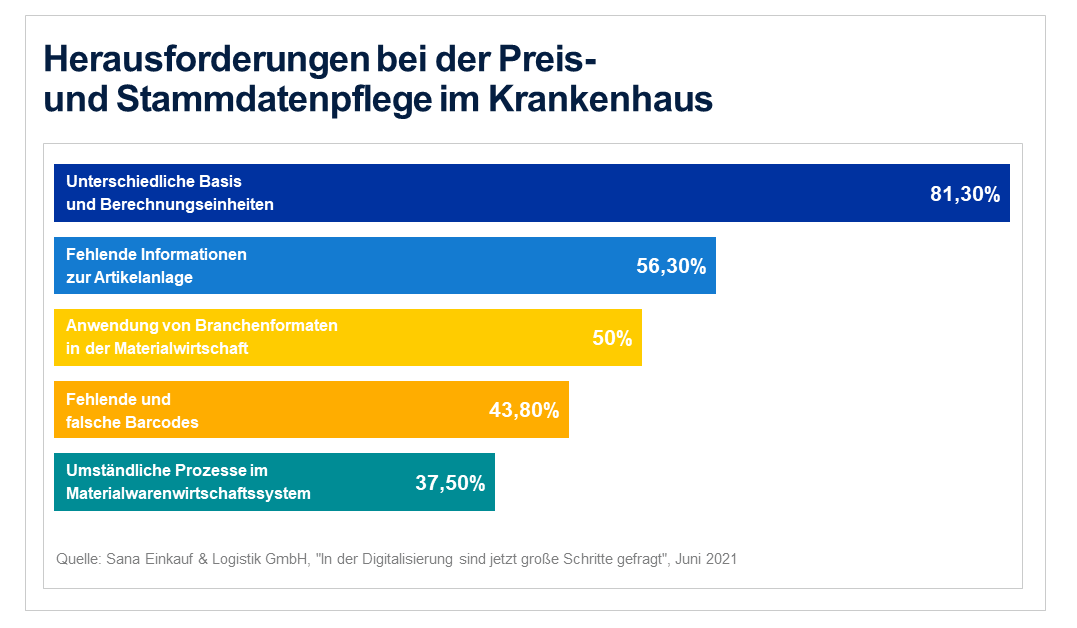
Hier wird deutlich, dass die Stammdatenpflege nicht nur wegen struktureller Probleme zur Herausforderung wird, sondern auch Schlüsselinformationen fehlen, um automatisierte Prozesse zu etablieren. Bestes Beispiel: unzureichende Barcode-Informationen. Wenn falsche oder gar keine GTIN-Barcodes oder logistische Informationen bereitgestellt werden, fehlt die Grundlage für eine Automation der Beschaffungsprozesse.
Die Folge: Steigende Kosten in den nachgelagerten Prozessen
Das Problem an der Geschichte ist, dass sich die fehlende Datentiefe oder fehlerhafte Produktdaten wie ein Rattenschwanz durch die unterschiedlichen Abteilungen von Krankenhäusern ziehen. Haben sich Fehler in die statischen Produktstammdaten eingeschlichen, so hat dies nämlich auch immer folgenschwere Auswirkungen auf die dynamischen Transaktionsdaten. Und weil Transaktionsdaten wie Bestellung, Lieferschein oder Rechnung auf den Produktstammdaten basieren, vervielfachen sich die Fehler.
In der Folge entstehen Kosten in den nachgelagerten Prozessen, die zeit- und ressourcenintensiv sind. Natürlich können Lieferanten einen georderten Artikel trotz falscher Produktdaten in der Bestellung identifizieren und den gewünschten Artikel liefern; auf Seiten des Krankenhauses entsteht trotzdem unnötige Arbeit, weil Lieferschein und Rechnung nicht mit der tatsächlichen Bestellung übereinstimmen, sodass Mitarbeiter im Wareneingang sowie in der Finanzabteilung auf Fehlersuche gehen müssen.
Die Gründe: Herausforderungen im Datenmanagement für Lieferanten und Krankenhäuser
Die beiden Studien machen einerseits deutlich, dass die Entscheider den Stellenwert von sauberen, verlässlichen Daten erkannt haben, andererseits zeigen die daraus abgeleiteten Gedanken aber auch, dass es im Bereich der Stammdatenpflege vier grundsätzliche Herausforderungen gibt:
- Nutzung unterschiedlicher Dateiformate
- Fehlerhafte Daten (bspw. veraltete Preise oder falsche Verpackungseinheiten)
- Fehlende Datentiefe (bspw. Klassifizierungen oder Barcode-Informationen)
- Manuelle und damit ineffiziente Prozesse für die Stammdatenpflege im Krankenhaus
Es muss klar sein, dass die Synchronisation von Produktdaten mit Artikel- und Preisinformationen eine partnerschaftliche Aufgabe ist. Lieferanten bzw. Hersteller und Krankenhäuser müssen die Herausforderungen gemeinsam angehen, um die Grundlage für kontaktlose Bestellungen zu legen und die Patientenergebnisse zu verbessern – was zugebenermaßen eine Herkulesaufgabe ist, weil nicht nur die Anforderungen an die Datenqualität im Gesundheitswesen besonders hoch sind, sondern sich die Produkt- und Preisinformationen von medizinischen Produkten auch häufig ändern.
Der Prozess: Fünf Schritte auf den Weg zu einer besseren Stammdatenqualität im Krankenhaus
Gefragt sind deshalb automatisierte Prozesse, die es beiden Seiten einfacher machen, Produktinformationen unkompliziert bereitzustellen, sie effizient zu verwalten und nahtlos in die Materialwirtschaft zu integrieren. Dabei kann ein Fünf-Phasen-Modell helfen, die Datenqualität nicht nur einmalig zu erhöhen, sondern sie auch dauerhaft hochzuhalten.
Phase 1: Bereitstellung valider Produktinformationen durch die Lieferanten
Zunächst müssen die Produktkataloge der Lieferanten den Weg ins Krankenhaus finden. Dabei ist es essenziell, dass die Produktinformationen korrekt und umfassend sind. Sichergestellt wird dies durch neutrale Organisationen, die es sich zur Aufgabe gemacht haben, die bereitgestellten Daten auf Basis von Regelwerken mit Prüfparametern zu validieren.
Im Gesundheitswesen gehören dazu vor allem die Validierungs-Regelwerke des Global Data Synchronization Networks (GDSN) sowie die Content Validation Network (COVIN) Regeln. Setzen Lieferanten für die Bereitstellung ihrer Produktinformationen auf Katalogaustausch-Formate mit entsprechenden Prüfparametern, wird sichergestellt, dass Krankenhäusern eine valide Grundlage für die Anlage ihrer Stammdaten zur Verfügung steht, um einerseits die Datenqualität in ihrer Materialwirtschaft zu erhöhen, und andererseits digitale Lösungen für die Beschaffung einzuführen.
Phase 2: Bündelung und Kuratierung von Produktkatalogen
Im nächsten Schritt gilt es, die einzelnen Produktkataloge in einem zentralen Datenpool zusammenzuführen. Krankenhäuser benötigen eine Single Source of Truth für hochwertige Artikel- und Preisdaten, die im Idealfall kuratiert werden. Bedeutet: Die Produktinformationen der Lieferanten werden bei Bedarf um fehlende Informationen (bspw. Barcodes) oder zusätzliche Attribute wie Klassifizierungen (bspw. ECLASS) oder Zertifikate (bspw. MDR) angereichert und so aufbereitet, dass Artikel schnell gefunden und einfach mit Produktäquivalenten verglichen werden können.
Phase 3: Synchronisation von Lieferanten- und Krankenhausdaten
Beide Seiten der Lieferkette, Krankenhäuser und Lieferanten, sind daran interessiert, dass ihre Daten übereinstimmen. Dafür müssen die Artikel- und Preisinformationen in der dritten Phase synchronisiert werden. Während dieser Prozess in vielen Organisationen manuell abläuft, ist es ratsam, hier auf Data Mapping Services zu setzen, also dem automatisierten Abgleich der Daten. Sofern die Informationen nicht übereinstimmen, sollten Krankenhäuser in der Lage sein, die Daten zu prüfen und bei Bedarf auf Knopfdruck zu aktualisieren, oder – falls keine Prüfung erforderlich ist – die Lieferantendaten für einen gesamten Produktkatalog zu übernehmen.
Phase 4: Integration der Daten in die Materialwirtschaft des Krankenhauses
Weil Krankenhäuser ihre Bestellungen in der Regel über ihre Materialwirtschaft anstoßen, sollten die validierten, angereicherten und synchronen Daten im vierten Schritt den Weg in die Klinik-Systeme finden. Dafür muss der Datenpool für das Data Sourcing (Phase 2) und die Stammdatenpflege (Phase 3) mit der Materialwirtschaft vernetzt werden, praktischerweise über Schnittstellen, die nahtlose Datenflüsse gewährleisten. Intelligente Clearing-Features helfen Krankenhäusern dabei, die aktualisierten und hochwertigen Daten in wenigen Schritten in die eigenen Systeme zu übertragen.
Phase 5: Benachrichtigungen bei Updates von Produktkatalogen
Obwohl Stammdaten wie oben erwähnt statisch sind, kommt es bei medizinischen Produkten und Verbrauchsgütern häufig vor, dass sich die Produktinformationen ändern. Ein Artikel kann aus dem Sortiment genommen werden, vielleicht wird eine neue Verpackungseinheit eingeführt, vielleicht der Preis angepasst. Krankenhäuser müssen die Datenqualität in ihren Systemen also nicht nur einmalig erhöhen, sondern auch sicherstellen, dass die Artikel- und Preisinformationen langfristig fehlerfrei und umfassend sind.
Einfacher wird dies durch Katalog-Abonnements, die in dem bereits skizzierten Datenpool berücksichtigt werden sollten. Sofern sich Produktinformationen auf Seiten der Lieferanten ändern, erfolgt eine Benachrichtigung an die Krankenhäuser, die die aktualisierten Informationen schnell übernehmen können und so im Rahmen der Stammdatenpflege sicherstellen, dass die Datenqualität in ihrer Materialwirtschaft auch dauerhaft hoch bleibt.
Die Erkenntnis: Effiziente Stammpflege im Krankenhaus geht nur über digitale Lösungen
Es liegt auf der Hand, dass dieses Fünf-Phasen-Modell eine digitale Transformation der Prozesse im Krankenhaus erfordert. Anstatt manuelle Abläufe beizubehalten, Excel-Listen zu pflegen und Daten per Hand in die Materialwirtschaft zu übertragen, sollten Krankenhäuser die Prozesse für die Stammdatenpflege automatisieren. Nötig ist ein zentraler Datenpool, der nicht nur die wichtigsten Produktkataloge der Lieferanten im Gesundheitswesen bündelt, sondern Krankenhäuser auch in die Lage versetzt, die kuratierten Artikel- und Preisinformationen zu verwalten und in wenigen Schritten in ihre Materialwirtschaft zu übertragen.
Durch die Verbesserung der Stammdatenqualität legen Gesundheitsorganisationen die Grundlage für optimierte Prozesse – im Einkauf, der Bestandsverwaltung, im Wareneingang und in der Finanzbuchhaltung. Dies setzt einerseits Ressourcen frei und führt damit zu einer Senkung der nachgelagerten Prozesskosten, andererseits steigt auch die Versorgungssicherheit. Eine hohe Stammdatenqualität im Krankenhaus lohnt sich also nicht nur finanziell. Sie trägt auch maßgeblich dazu bei, die Patientenergebnisse zu verbessern.
Adrian Bedö
Senior Product Manager Content Solutions
Adrian Bedö, Senior Product Manager Content Solutions bei GHX Europe, ist ein ausgewiesener Produktmanagement-Experte mit mehr als 12 Jahren Erfahrung in der B2B-Software-Branche. Mit seinem Fachwissen, das er aus seiner langjährigen Vergangenheit im Management von End-to-End-Produktlebenszyklen für Software as a Service (SaaS)-Lösungen zieht, konzentriert sich Adrian Bedö auf die Entwicklung und Bereitstellung hochwertiger Technologien für das Content Management und die Stammdatenpflege im Gesundheitswesen.